Fun with Unicode in Java
Normally we don’t pay much attention to character encoding in Java. However, when we crisscross byte and char streams, things can get confusing unless we know the charset basics. Many tutorials and posts about character encoding are heavy in theory with little real examples. In this post, we try to demystify Unicode with easy to grasp examples.
Encode and Decode
Before diving into Unicode, first let’s understand terms - encode and decode. Suppose we capture a video in mpeg format, the encoder in the camera encodes the pixels into bytes and when played back, the decoder coverts back the bytes to pixels. Similar process plays out when we create a text file. For example, when letter H is typed in a text editor, the OS encodes the keystroke as byte 0x48 and pass it to editor. The editor holds the bytes in its buffer and pass it on to windowing system which decodes and displays the byte 0x48 as H. When file is saved, 0x48 gets into the file.
In short, encoder converts items such as pixels, audio stream or characters as binary bytes and decoder reconverts the bytes back original form.
Encode and Decode Java String
Let’s go ahead and encode some strings in Java.
public class StringEncoder {
public static void main(String[] args) {
String str = "Hello";
byte[] bytes = str.getBytes(StandardCharsets.US_ASCII);
printBytes(bytes);
}
public static void printBytes(byte[] a) {
StringBuilder sb = new StringBuilder();
for (byte b : a) {
sb.append(String.format("x%02x ", b));
}
System.out.println(sb);
}
}
The String.getBytes() method encodes the string as bytes (binary) using US_ASCII charset and printBytes() method outputs bytes in hex format. The hex output 0x48 0x65 0x6c 0x6c 0x6f is binary of form string Hello in ASCII.
Next, let’s see how to decode the bytes back as string.
public class StringDecoder {
public static void main(String[] args) {
byte[] bytes = {0x48, 0x65, 0x6c, 0x6c, 0x6f};
String str = new String(bytes, StandardCharsets.US_ASCII);
System.out.println(str);
}
}
Here we decode byte array filled with 0x48 0x65 0x6c 0x6c 0x6f as a new string. The String class decodes the bytes with US_ASCII charset which is displayed as Hello.
We can omit StandardCharsets.US_ASCII argument in new String(bytes) and str.getBytes(). The results will be same as default charset of Java is UTF-8 which use same hex value for English alphabets as US_ASCII.
The ASCII encoding scheme is quite simple where each character is mapped to a single byte, for example, H is encoded as 0x48, e as 0x65 and so on. It can handle English character set, numbers and control characters such as backspace, carriage return etc., but not many western or asian language characters etc.
Say Hello in Mandarin
Hello in Mandarin is nĭ hăo. It is written using two characters 你 (nĭ) and 好 (hăo). Let’s encode and decode single character 你 (nĭ).
// encode
String str = "你";
byte[] bytes = str.getBytes(StandardCharsets.UTF_8);
printBytes(bytes); // xe4 xbd xa0 (3 bytes)
// decode
String decodedStr = new String(bytes, StandardCharsets.UTF_8);
System.out.println(decodedStr); // 你
Encoding the character 你 with UTF-8 character set returns an array of 3 bytes xe4 xbd xa0, which on decode, returns 你.
Let’s do the same with another standard character set UTF_16.
// encode
String str = "你";
byte[] bytes = str.getBytes(StandardCharsets.UTF_16);
printBytes(bytes); // xfe xff x4f x60 (4 bytes)
// decode
String decodedStr = new String(bytes, StandardCharsets.UTF_16);
System.out.println(decodedStr); // 你
Character set UTF_16 encodes 你 into 4 bytes - xfe xff x4f x60 while UTF_8 manages it with 3 bytes.
Just for heck of it, try to encode 你 with US_ASCII and it returns single byte x3f which decodes to ? character. This is because ASCII is single byte encoding scheme which can’t handle characters other than English alphabets.
Introducing Unicode
Unicode is coded character set (or simply character set) capable of representing most of the writing systems. The recent version of Unicode contains around 138,000 characters covering 150 modern and historic languages and scripts, as well as symbol sets and emoji. The below table shows how some characters from different languages are represent in Unicode.
| Character | Code Point | UTF_8 | UTF_16 | Language |
|---|---|---|---|---|
| a | U+0061 | 61 | 00 61 | English |
| Z | U+005A | 5a | 00 5a | English |
| â | U+00E2 | c3 a2 | 00 e2 | Latin |
| Δ | U+0394 | ce 94 | 03 94 | Latin |
| ع | U+0639 | d8 b9 | 06 39 | Arabic |
| 你 | U+4F60 | e4 bd a0 | 4f 60 | Chinese |
| 好 | U+597D | e5 a5 bd | 59 7d | Chinese |
| ಡ | U+0CA1 | e0 b2 a1 | 0c a1 | Kannada |
| ತ | U+0CA4 | e0 b2 a4 | 0c a4 | Kannada |
Each character or symbol is represented by an unique Code point. Unicode has 1,112,064 code points out of which around 138,000 are presently defined. Unicode code point is represented as U+xxxx where U signifies it as Unicode. The String.codePointAt(int index) method returns code point for character.
String str = "你";
int codePoint = str.codePointAt(0);
System.out.format("U+%04X", codePoint);
// outputs the code point - U+4F60
A charset can have one or more encoding schemes and Unicode has multiple encoding schemes such as UTF_8, UTF_16, UTF_16LE and UTF_16BE that maps code point to bytes.
UTF-8
UTF-8 (8-bit Unicode Transformation Format) is a variable width character encoding capable of encoding all valid Unicode code points using one to four 8-bit bytes. In the above table, we can see that the length of encoded bytes varies from 1 to 3 bytes for UTF-8. Majority of web pages use UTF-8.
The first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single byte with the same binary value as ASCII. The valid ASCII text is valid UTF-8-encoded Unicode as well.
UTF-16
UTF-16 (16-bit Unicode Transformation Format) is another encoding scheme capable of handling all characters of Unicode character set. The encoding is variable-length, as code points are encoded with one or two 16-bit code units (i.e minimum 2 bytes and maximum 4 bytes).
Many systems such as Windows, Java and JavaScript, internally, uses UTF-16. It is also often used for plain text and for word-processing data files on Windows, but rarely used for files on Unix/Linux or macOS.
Java internally uses UTF-16. From Java 9 onwards, to reduce the memory taken by String objects, it uses either ISO-8859-1/Latin-1 (one byte per character) or UTF-16 (two bytes per character) based upon the contents of the string. JEPS 254.
However don’t confuse the internal charset with Java default charset which is UTF-8. For example, the Strings live in heap memory as UTF-16, however the method String.getBytes() returns bytes encoded as UTF-8, the default charset.
You can use CharInfo.java to display character details of a string.
To summarize:
- Character set is collection of characters. Numbers, alphabets and Chinese characters are examples of character sets.
- Coded character set is a character set in which each character has an assigned int value. Unicode, US-ASCII and ISO-8859-1 are examples of coded character set.
- Code Point is an integer assigned to a character in a coded character set.
- Character encoding maps between code points of a coded character set and sequences of bytes. One coded character set may have one or more character encodings . For example, ASCII has one encoding scheme while Unicode has multiple encoding schemes - UTF-8, UTF-16, UTF_16BE, UTF_16LE etc.
Java IO
Use char stream IO classes Reader and Writer while dealing with text and text files. As already explained, the default charset of Java platform is UTF-8 and text written using Writer class is encoded in UTF-8 and Reader class reads the text in UTF-8.
Using java.io package, we can write and read a text file in default charset as below.
String str = "a Z â Δ 你 好 ಡ ತ ع";
File file = new File("x-utf8.txt");
// write file in default charset (UTF-8)
try (BufferedWriter out = new BufferedWriter(new FileWriter(file))) {
out.write(str);
}
// read file in default charset (UTF-8)
try (BufferedReader in = new BufferedReader(new FileReader(file))) {
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
}
The above example, uses char stream classes - Writer and Reader - directly that uses default character set (UTF-8).
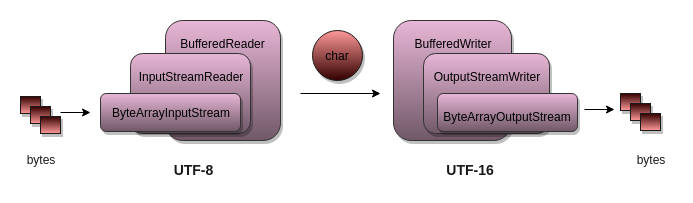
To encode/decode in non-default charset use byte oriented classes and use a bridge class to convert it char oriented class. For example, to read file as raw bytes use FileInputStream and wrap it with InputStreamReader, a bridge that can encode the bytes to chars in specified charset. Similarly for output, use OutputStreamWriter (bridge) and FileOutputWriter (byte output)
// read in UTF_16LE
InputStream byteInStream = new FileInputStream(file);
Reader encodedCharStream =
new InputStreamReader(byteInStream, StandardCharsets.UTF_16LE);
// write in UTF_16LE
OutputStream byteOutStream = new FileOutputStream(file);
Writer decodedCharStream =
new OutputStreamWriter(byteOutStream, StandardCharsets.UTF_16LE);
Following example, writes a file in UTF_16BE charset and reads it back.
String str = "a Z â Δ 你 好 ಡ ತ ع";
Charset charset = StandardCharsets.UTF_16BE;
File file = new File("x-utf16be.txt");
// write file in non default charset
try (BufferedWriter out = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream(file), charset))) {
out.write(str);
}
// read file in non default charset
try (BufferedReader in = new BufferedReader(
new InputStreamReader(new FileInputStream(file), charset))) {
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
}
Transcoding
Transcoding is the direct digital-to-digital conversion from an encoding to another, such as UTF-8 to UTF-16. We regularly encounter transcoding in video, audio and image files but rarely with text files.
Imagine, we receive a stream of bytes over the network encoded in CP-1252 (Windows-1252) or ISO 8859-1 and want to save it to text file in UTF 8.
There are couple of options to transcode from one charset to another. The easiest way to transcode it to use String class.
String str = new String(bytes, StandardCharsets.ISO_8859_1);
byte[] toBytes = str.getBytes(StandardCharsets.UTF_8);
While this quite fast, it suffers when we deal with large set of byte as heap memory gets allocated to multiple large strings. Better option is to use java.io classes as shown below:
See Transcode.java for transcoding example and Char Server for a rough take on encoding between server and socket.
Play with Unicode in Linux terminal
We can work with text encoding in Linux terminal with some simple commands. Note that Linux terminal can display ASCII and UTF-8 files but not UTF-16.
# create a text file from encoded bytes
$ echo -n -e '\xce\x94' > delta-8.txt
$ echo -n -e '\xfe\xff\x03\x94' > delta-16.txt
$ echo -n -e '\xe4\xbd\xa0\x20\xe5\xa5\xbd' > nihou-8.txt
$ echo -n -e '\xfe\xff\x4f\x60\xfe\xff\x20\x59\x7d' > nihou-16.txt
# debug a text file as hex
$ hd nihou-16.txt
00000000 fe ff 4f 60 fe ff 20 59 7d |..O`.. Y}|
00000009
# know file encoding scheme
$ file -i *.txt
delta-16.txt: text/plain; charset=utf-16be
delta-8.txt: text/plain; charset=utf-8
nihou-16.txt: text/plain; charset=utf-16be
nihou-8.txt: text/plain; charset=utf-8
# transcode from UTF 8 to UTF 16LE
$ iconv -f UTF8 -t UTF16LE < nihou-8.txt > nihou-16le.txt
# list encoding schemes
$ iconv -l
# read a file in default charset
$ gedit nihou-8.txt
# non-default
$ gedit --encoding UTF-16LE nihou-16le.txt
Further Reading
Some good posts about Unicode usage in Java.
The Absolute Minimum Developers should know about Unicode and Character Sets
Java: a rough guide to character encoding
Don’t form strings containing partial characters from variable-width encodings