In this chapter we describe how to build query using JSoup Selectors and same holds good for XPath while using HtmlUnit.
Selectors
In Example 1, we query price data from defs/examples/page/acme-quote.html page. The price snippet from this page is
<div id="price_tick">
<span id="price_tick_span">
<strong>315.25</strong>
</span>
</div>
To access the value the JSoup selector is
div#price_tick/*
Use Chrome to get Selector
Chrome browser can assist you in constructing the Selector or XPath. To do that, open the HTML page in Chrome and select the item which we are interested. Next, right click to open the context menu and select Inspect from the list to open the Inspect panel. Then in Inspect panel, select the highlighted item and right click and select copy menu.
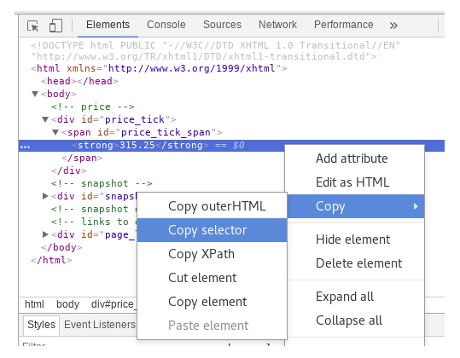
In Copy, we have option, among other things, to copy the Selector or XPath to clipboard. Copy and paste the selector to editor. For price, selector provided by chrome is
#price_tick_span > strong
We are using slightly different selector in the example as selectors can be constructed with different elements.
JSoup Selector Syntax
To access complex items, we may have to use functions to access specific item. Learn more about selector in Selector Syntax and JSoup Selector API.
Query - Region and Field
Selector has to be further split into region and field to optimize the query performance.
For example, take the case of table
....
....
<table>
<tr>
<td colspan="1">Sources of Funds</td>
....
</tr>
<tr>
<td colspan="1">Share Capital</td>
<td>804.72</td>
<td>801.55</td>
<td>795.32</td>
<td>790.18</td>
<td>781.84</td>
</tr>
The selector to access table data is
table:contains(Sources Of Funds) > tr:nth-child(2) > td:nth-child(1)
In case we use the selector to get each and every <td> item in table, JSoup has to parse the entire page, build DOM from it and then zero in on particular node for each item. Data rich pages may have hundreds of node and then parse becomes quite expensive.
To optimize the parse, we need to split the selector into two components
- region and field. The query, after the split, becomes
<axis name="row">
<xf:fields>
<xf:query region="table:contains(Sources Of Funds)"
field="tr:nth-child(2) > td:nth-child(1)" />
</xf:fields>
Now, Gotz fires the region query first and parse the table and its child nodes and caches it in a HashMap. Next, it fires the field query on the cached table, instead of entire page, to get the target node. As cached region nodes are subset of entire page, fields selector query the subset instead of entire page.
For each region query, Gotz first consult the cache and if it finds it in cache then it is reused. Otherwise, if region is not found in cache then only page is parsed and cached for reuse.
While splitting the selector, put the top most element of the area which we are interested in region attribute and the selector to access its children in the field attribute. In the above example, it is quite natural to select and cache the table as it is top most element of the area we are interested in and subsequently, access its children repeatedly with field selector.
Dynamic Query
When scraping single data point, we can hard code the selector as
<xf:query region="table:contains(Sources Of Funds)"
field="tr:nth-child(2) > td:nth-child(1)" />
But, to access next <tr> we need another query with field as tr:nth-child(3) > td:nth-child(1). To access a table with 5 cols and 4 rows, we need to define 20 queries.
Instead, we can use Gotz dynamic query feature. The hard coded query can be converted into dynamic query with substitution variables.
<xf:query region="table:contains(Sources Of Funds)"
field="tr:nth-child(%{row.index}) > td:nth-child(1)" />
Gotz dynamically substitute the variable %{row.index} with the index value of the member and fires the query. With the dynamic query, we can scrape any number of rows or cols with single query.
Allowed variables are
%{col.index}
%{col.match}
%{row.index}
%{row.match}
The subsequent chapters covers dynamic queries extensively with examples.